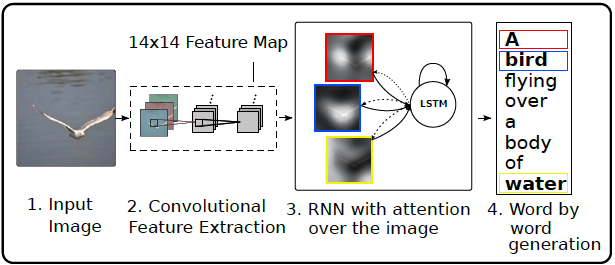
Neural architecture search with reinforcement learning (Arxiv 2017)
- Neural architecture search with reinforcement learning
- 주저자: Barret Zoph (Google Brain)
the structure and connectivity of a neural network can be typically specified by a variable-length string. It is therefore possible to use a recurrent network – the controller – to generate such string.
a simple method of using a recurrent network to generate convolutional architectures.
a simple method of using a recurrent network to generate convolutional architectures.
the recurrent network can be trained with a policy gradient method to maximize the expected accuracy of the sampled architectures






- GENERATE MODEL DESCRIPTIONS WITH A CONTROLLER RECURRENT NEURAL NETWORK
- we use a controller to generate architectural hyperparameters of neural networks. To be flexible, the controller is implemented as a recurrent neural network. Let’s suppose we would like to predict feedforward neural networks with only convolutional layers, we can use the controller to generate their hyperparameters as a sequence of tokens:
- In our experiments, the process of generating an architecture stops if the number of layers exceeds a certain value.
- Once the
- controller RNN (with parameter thetac finishes generating an architecture, a neural network with this architecture is built and trained.

- TRAINING WITH REINFORCE
- The list of tokens that the controller predicts can be viewed as a list of actions a1:T to design an architecture for a child network
- At convergence, this child network will achieve an accuracy R on a held-out dataset. We can use this accuracy R as the reward signal and use reinforcement learning to train the controller. More concretely, to find the optimal architecture, we ask our controller to maximize its expected reward,

- Since the reward signal R is non-differentiable, we need to use a policy gradient method to iteratively update RNN parameter (thetac)

- An empirical approximation of the above quantity is:

- Where m is the number of different architectures that the controller samples in one batch and T is the number of hyperparameters our controller has to predict to design a neural network architecture.
- The validation accuracy that the k-th neural network architecture achieves after being trained on a training dataset is Rk.
- 위 수식은 unbiased estimation 이나, estimate variance 가 크다. Variance 를 줄여주기 위해 base function b 를 적용한다. b 는 이전 구조들의 accuracy 에 대한 exponential moving average function 이다. (b 가 current action 에 의해 영향을 받으면, 아래 수식은 여전히 unbiased estimate 이다)

- Accelerate Training with Parallelism and Asynchronous Updates
- As training a child network can take hours, we use distributed training and asynchronous parameter updates in order to speed up the learning process of the controller