Recurrent models of visual attention (NIPS 2014)
- 논문 제목: Recurrent models of visual attention. In Advances in neural information processing systems
- 주 저자: Volodymyr Mnih (구글 딥마인드)
- 연구 기관: 구글 딥마인드
일반적으로 CNN (Convolutional Neural Network) 은 이미지 내의 모든 영역에 대해 convolution kernel, pooling, non-linear activation function, normalization 등을 계층적으로 적용하여 최종 feature map 을 생성한 후, 최종 feature map 에 대해 classification, detection, segmentation 등을 적용한다. 이 경우, 분석해야 할 영역 이 외의 나머지 모든 영역들에 대해서도 CNN 을 적용함으로써 과다한 연산량이 소모될 뿐 아니라, 중요한 정보가 있는 영역 외의 정보들이 최종 레이어로 전달되므로 분석에 있어 일종의 'noise' 요인이 될 수 있다.
본 연구는 attention model 을 단문자 인식에 적용한 것으로써, 문자 라인을 형성하는 주요 영역들을 순차적으로 찾아내고, 주요 영역에 국한되는 'local CNN' 을 적용하는 기술이다. 이렇게 함으로써 배경 영역에 대한 분석을 제거하여 불필요한 연산량을 과도하게 소모하지 않고, 주요 영역에 집중하여 분석을 수행할 수 있게 한다. 이러한 처리 과정은 인간이 이미지 내의 객체를 바라볼 때, 배경에 신경쓰지 않고 보고자 하는 객체 영역의 여러 국지적 모양을 훑어보는 것을 모방한 것이다.
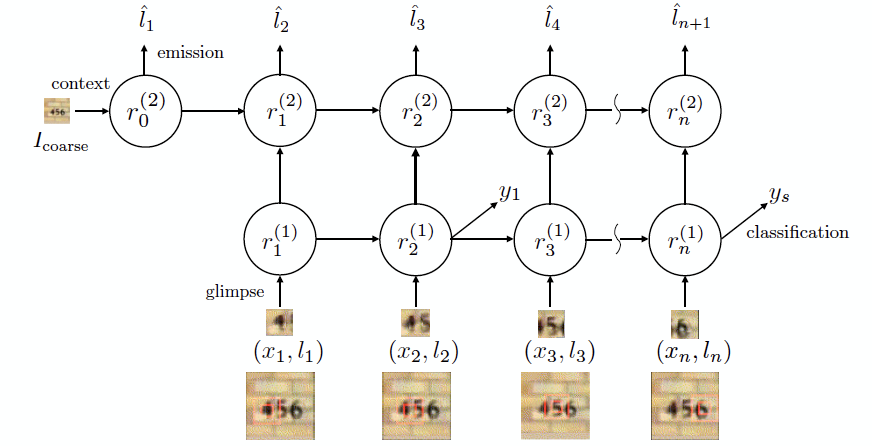
기술 구조는 크게 세 가지로 구성된다.
기술 구조는 크게 세 가지로 구성된다.
- Glimpse Sensor
- 이전 시점의 location 정보 (lt-1) 및 이미지를 입력받아서 그 위치에 해당하는 'local' image patch ⍴(xt, lt-1) 생성 (아래 그림의 A)
- Glimpse Network
- Glimpse sensor 에서 생성한 local image patch 와 location 정보를 조합하여 최종 glimpse representation (gt) 생성 (아래 그림의 B)
- Model Architecture
- Glimpse representation 을 입력받아서 다음 시점에서 분석해야 할 location 정보 (lt) 및 lt-1 위치의 action at 출력하는 RNN architecture (본 연구에서의 action 은 숫자 classification 임) (아래 그림의 C)

상기 네트워크는 일련의 decision sequence 를 출력하는 것으로 볼 수 있다 (매 시점마다 action 과 location 정보를 출력함). 파라메터 최적화는, 일련의 decision sequence 에 따른 보상 (reward R) 이 최대화 될 수 있도록 하는 것이다. 즉, 정답을 출력하는 decision sequence (episode) 는 큰 보상을 할당하고, 오답을 출력하는 decision sequence 는 보상을 할당하지 않는다. 모든 episode 에 대한 보상을 계산하는 것은 너무 많은 연산량이 필요하므로 현실적으로 어렵다. 따라서 Monte Carlo sampling 을 통해 유의미한 episode 를 sampling 하고, 유의미한 episode 에 대한 gradient 평균을 통해 근사화 하여 최적화를 진행한다. 이러한 최적화 과정은 reinforcement learning 과정과 일치한다.

본 연구는 숫자 1개에 대한 인식을 수행하는 것에 적용하였으나, 후속 연구에서는 본 연구보다 진보한 attention + RNN 구조를 여러 문자로 구성된 문자열 인식에 적용하였다. 본 연구와 관련된 자세한 내용은 후속 연구인 아래 논문 리뷰에서 다루기로 한다.
본 블로그에 아래 후속 논문에 대한 자세한 리뷰를 게재하였으며, 여기를 클릭하면 볼 수 있다.
- 본 연구의 후속 연구 논문