Show, attend and tell: Neural image caption generation with visual attention (ICML 2015)
- 논문 제목: Show, attend and tell: Neural image caption generation with visual attention
- 주 저자: Kelvin Xu (몬트리올 대학)
- 참여 연구 기관: 몬트리올 대학, 토론토 대학
요즘 들어 주목받고 있는 attention model 에 관한 연구이다. Attention model 은 시계열 분석 모델에서 처음 적용되기 시작했다. 대표적인 논문 중 하나는 Bahdanau 가 기계 번역에 적용한 아래 논문이다. Bahdanau 는 기계 번역을 위해 Bi-LSTM 구조를 채용하고, 현재 시점을 중심으로 일정 time window 에 포함되는 LSTM hidden state 의 가중합으로 출력값을 추정한다. 이 때, hidden state 에 대한 가중치가 attention model 의 추정값이 된다.
(Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.)
[ Network Architecture ]
[ Network Architecture ]
최근 들어 attention model 을 computer vision 분야에 적용하는 논문들이 발표되고 있다. 여기서 소개하는 논문은 이미지가 한 장 주어졌을 때, 이미지를 설명하는 문장을 생성하는 image captioning 기술에 관한 것이다.
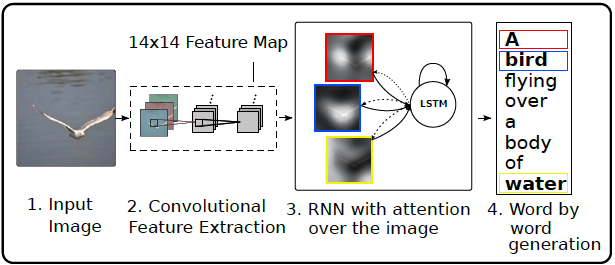
Image captioning을 위해서는 이미지 내에 어떠한 'context'가 내재되어 있는지 분석해야 한다. 본 논문에서는 context 분석 시 이미지 내에서 어느 위치를 주목해서 봐야하는지 attention model 을 이용하여 추정하고 있다. 아래 그림에서 본 논문의 전체적인 기술 구조를 도식화하였다.
Image captioning을 위해서는 이미지 내에 어떠한 'context'가 내재되어 있는지 분석해야 한다. 본 논문에서는 context 분석 시 이미지 내에서 어느 위치를 주목해서 봐야하는지 attention model 을 이용하여 추정하고 있다. 아래 그림에서 본 논문의 전체적인 기술 구조를 도식화하였다.

위 그림에서 보여지듯이, 전체적인 구조는 encoder-decoder 구조를 채택하고 있다.
CNN (Convolutional Neural Network) 을 이용하여 각 위치별 특징 벡터를 생성하고 (feature vector set), 특징 벡터에 attention model 을 적용하여 LSTM (Long-Short Term Memory) 입력 벡터 z를 생성하며, 최종적으로 LSTM에 기반하여 문장을 형성하는 단어를 순차적으로 출력하는 구조이다. 현재 시점 t 에서의 caption 출력을 위해 '특정 위치'에서 생성된 feature vector 에 가중치를 주는 방식이다. 즉, caption 하나를 생성할 때 마다 특정 위치를 참조하게 만든 구조이다. CNN 출력 feature vector set 의 각 벡터는 이미지 내 특정 위치에서의 정보를 담고있으며, CNN 구조로는 GoogLeNet, VGG, AlexNet 구조를 채택하였다.
LSTM의 입력은 최종 출력값 (output caption)과 feature vector를 조합하여 구성하는 multi-modal embedding 구조를 채용하였다. Multi-modal embedding 구조는 (Karpathy, 2015) 제안을 따랐다. Multi-modal embedding 구조는 현재 시점의 출력 caption yt 를 LSTM 에 재입력 함으로써, 이전에 출력한 모든 caption 에 대한 정보를 LSTM 이 저장하여 다음 시점 t+1 에서 출력해야 할 caption 에 대한 정보 추정을 용이하게 한다.
위 그림에서 Lz, Lh, Lo 및 Embedding E 는 서로 다른 차원의 벡터에 대해 element-wise 연산을 적용하기 위한, 차원 변환 매트릭스라고 볼 수 있다.
LSTM 학습 시, memory 및 hidden state 초기화는 feature vector 평균 값을 이용하여 설정한다. (논문에 finit,c 와 finit,h 에 대한 설명은 기술되어 있지 않다.)

Attention model ⏀는 L개 feature vector 에 부여될 가중치를 결정한다. 가중치는 0 ~ 1 사이의 값을 가지며 모든 가중치의 합이 1이 되는 deterministic soft attention model 과 각 가중치가 0 또는 1의 값을 가지는 stochastic hard attention model 두 가지 형태가 있다.
[ Stochastic Hard Attention Model ]
Stochastic hard attention 은 가중치가 0 또는 1 이며, 아래 그림 및 수식과 같이 나타낼 수 있다. st,i 는 0 또는 1이며 어느 위치를 지정할 것인가에 대한 location variable 로 볼 수 있다. Alpha value 계산까지는 soft attention 과 동일하나, 최종 가중치가 0 또는 1로 설정되는 과정이 alpha 와 feature vector 가 주어질 때의 multinoulli distribution sampling 인 것만 다르다.


Stochastic hard attention 은 가중치가 0 또는 1 이며, 아래 그림 및 수식과 같이 나타낼 수 있다. st,i 는 0 또는 1이며 어느 위치를 지정할 것인가에 대한 location variable 로 볼 수 있다. Alpha value 계산까지는 soft attention 과 동일하나, 최종 가중치가 0 또는 1로 설정되는 과정이 alpha 와 feature vector 가 주어질 때의 multinoulli distribution sampling 인 것만 다르다.

Stochastic hard attention 학습 방법은 Monte Carlo sampling 방식으로 진행한다. 아래 수식의 variational lower bound on the marginal log-likelihood 손실에 대해 최적화하여 hard attention 'Wh' parameter 를 학습한다. (참고: 아래 수식의 W 에는 아래 첨자 h가 빠져 있다.)

위 수식에서, 모든 경우의 s 에 대해 (즉, 모든 시점 t 마다 선택 가능한 모든 location 조합에 대해) 손실을 최적화하는 것은 현실적으로 어려움이 있다. 따라서, 아래 수식과 같이 각 시점 t에 대해 multinoulli distribution 으로 location sampling 을 적용하고, 이들 sample 조합에 대한 평균으로 log-likelhood를 근사화 하는 방법을 적용하였다 (Monte Carlo sampling).



위 수식은 "attention choosing a sequence of actions" 에 대한 보상을 최대화하는 것으로써, 강화학습 모델과 동일하다.
[ Deterministic Soft Attention Model ]
Deterministic soft attention model 은 multilayer perceptron Ws, softmax 함수 및 element-wise dot product 로 구성되어 있다. Multilayer perceptron 'Ws' 는 feature vector set 과 LSTM 의 이전 시점 hidden state vector 를 입력받아서 이미지 내 어느 위치에 높은 가중치를 부여할지 결정하는 계수 e 를 출력한다. Softmax 함수는 계수 e 를 입력받아 계수의 dynamic range 를 0 ~ 1, summation 을 1로 만들어 최종 가중치를 생성한다. Dot product 은 가중치를 각 feature vector 에 부여하여 caption 생성을 위한 LSTM 으로 전달한다. Soft attention model 구조를 아래 그림에 나타내었다.



학습을 위해 hard attention 방식에서 사용한 sampling 이 필요없다. z vector 연산을 가중합으로 수행하고, 최종 손실로 부터의 back-propagation 을 통해 직접적인 파라메터 추정이 가능하다. 또한 attention weight 가 'object' 에 보다 집중하게 하기 위해서 hidden state t-1 로 부터 gating scalar beta 를 생성하고, 이를 attention model 에 반영한다.


학습 시, C 개 caption 을 생성할 동안 position i 의 time summation 이 1에 가깝게 되도록 유도 하는 방식으로 (즉, C 개 caption 생성을 위해 모든 position 이 동일한 중요도로 기여할 수 있도록 유도함) regularization 을 적용하는 것이 성능 향상에 중요하다.
최종 손실 함수는 아래와 같이 설정하였다.


[ 학습 ]
- DB
- Flickr8k dataset
- 8,000 images
- 5 reference sentences per image
- RMSProp optimizer 적용
- Flickr30k dataset
- 30,000 images
- 5 reference sentences per image
- RMSProp optimizer 적용
- MS COCO dataset
- 82,783 images
- image 당 5개 이상 sentence 있음 -> 5개 초과분은 무시
- Adam optimizer 적용
- Fixed vocabulary size of 10,000
- CNN 은 ImageNet 데이터셋으로 학습한 VGG 적용 (finetuning 하지 않았음).
- 14 x 14 x 512 feature vector set -> decoder vector dimension 은 196 x 512 (L x D)
- 하나의 mini-batch (size 64) 는 동일한 sentence length 를 가지도록 sampling (length 는 무작위 선택) -> 성능에 영향 없으면서 학습 속도 향상
- MS COCO 데이터셋 학습에 3일 소요 (NVIDIA Titan Black GPU)
[ 실험결과 ]



[ Reference ]
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Karpathy, A., & Fei-Fei, L. (2015). Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3128-3137).
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., ... & Rabinovich, A. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).