Multiple object recognition with visual attention (arXiv 2014)
- 논문 제목: Multiple object recognition with visual attention
- 주 저자: Jimmy Lei Ba (토론토 대학)
- 참여 연구 기관: 토론토 대학, 구글 딥마인드
본 연구는 아래 논문의 후속 연구로써, attention + RNN 구조를 문자열 인식에 적용한 기술이다. 아래 사전 연구 논문에 대한 간단한 리뷰는 여기를 클릭하면 볼 수 있다.
[ Network Architecture ]
사전 연구와 유사하게 본 연구는 이미지 내에서 문자 라인을 형성하는 주요 국지 영역들을 순차적으로 찾아내고, 주요 영역에만 국한되는 'local CNN' 을 적용하는 기술이다. 이렇게 함으로써 배경 영역에 대한 분석을 제거하여 불필요한 연산량을 과도하게 소모하지 않고, 주요 영역에 집중하여 분석을 수행할 수 있게 한다. 이러한 처리 과정은 인간이 이미지 내의 객체를 바라볼 때, 배경에 신경쓰지 않고 보고자 하는 객체 영역의 여러 국지적 모양을 훑어보는 것을 모방한 것이다.
본 연구에서 제안하는 기술 구조는 아래 그림과 같다. 아래 그림에서 'context', 'emission', 'glimpse', 'classification' 이 쓰여진 곳에는 각각의 목적에 맞는 neural network 이 위치하고 있다.
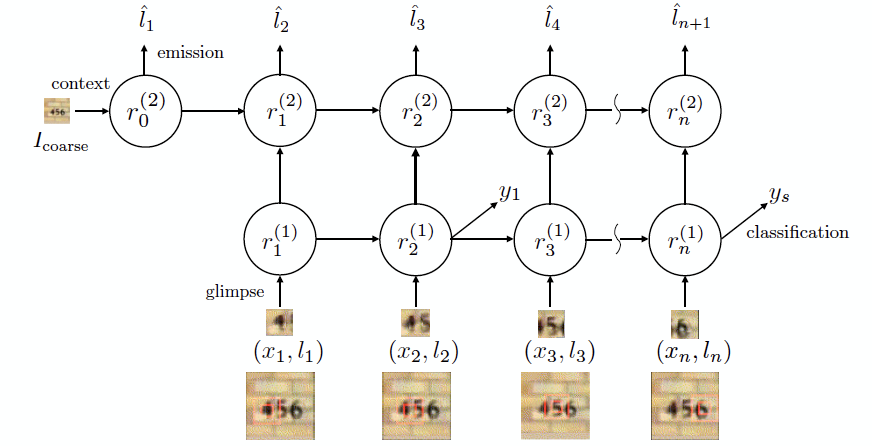
위 그림에서 나타나듯이 본 연구에서 제안하는 기술은 context, emission, glimpse, classification 및 recurrent network 으로 구성된다. 사전 연구에서 제안한 기술 구조에서 context 및 emission network 이 추가된 구조이다. 하나씩 살펴보자.

Recurrent network 을 두 개의 hidden layer 로 구성하여 2nd RNN hidden layer 가 이전 시점의 glimpse 정보 및 context 정보 (context 정보는 전체 이미지에 대한 정보가 담겨있다) 를 입력 받아서 다음 시점에서 분석해야 할 위치를 결정하는데 필요한 정보를 생성하게 한다. 1st RNN hidden layer 는 classification 을 위해 필요한 정보를 생성하는 역할을 한다.
이와 같이 RNN 을 2 개의 hidden layer 구조로 설계하여 context network 과 classification network 을 완전히 분리하였으며, 이는 classification network 이 전체 이미지 정보를 담고 있는 context network 출력을 이용할 수 없게 만든다. 만약 classification network 이 현 시점에서 출력해야 할 class index 추정 시, 전체 이미지 정보를 담고 있는 context network 출력을 이용하게 된다면 정확한 위치의 정보 이 외의 다른 위치 정보들 까지도 classification 에 활용할 수 있는 여지가 생기는 부정적 영향이 있다. Classifier 는 서로 다른 위치의 glimpse 정보를 조합하여 하나의 class index 를 출력하는 것이 더 바람직 하므로, classifier 는 contextual information 을 활용할 수 없는 구조 설계가 필요하다.
[ Learning Where and What ]
상기 네트워크는 일련의 decision sequence 를 출력하는 것으로써, decision sequence 의 결과가 true positive 를 출력하는 (즉, 큰 reward 를 받는) episode 는 학습에 반영하고, 그렇지 않은 episode 는 학습에 반영하지 않음으로써 최적화가 가능하다. 이는 reinforcement learning 과정과 매우 유사하다.

[ Demo ]
아래 동영상에서 local image patch 의 위치를 순차적으로 이동해 가며 이미지를 분석하는 모습을 볼 수 있다.
상기 네트워크는 일련의 decision sequence 를 출력하는 것으로써, decision sequence 의 결과가 true positive 를 출력하는 (즉, 큰 reward 를 받는) episode 는 학습에 반영하고, 그렇지 않은 episode 는 학습에 반영하지 않음으로써 최적화가 가능하다. 이는 reinforcement learning 과정과 매우 유사하다.
[ Demo ]
아래 동영상에서 local image patch 의 위치를 순차적으로 이동해 가며 이미지를 분석하는 모습을 볼 수 있다.