EAST: an efficient and accurate scene text detector (CVPR 2017)

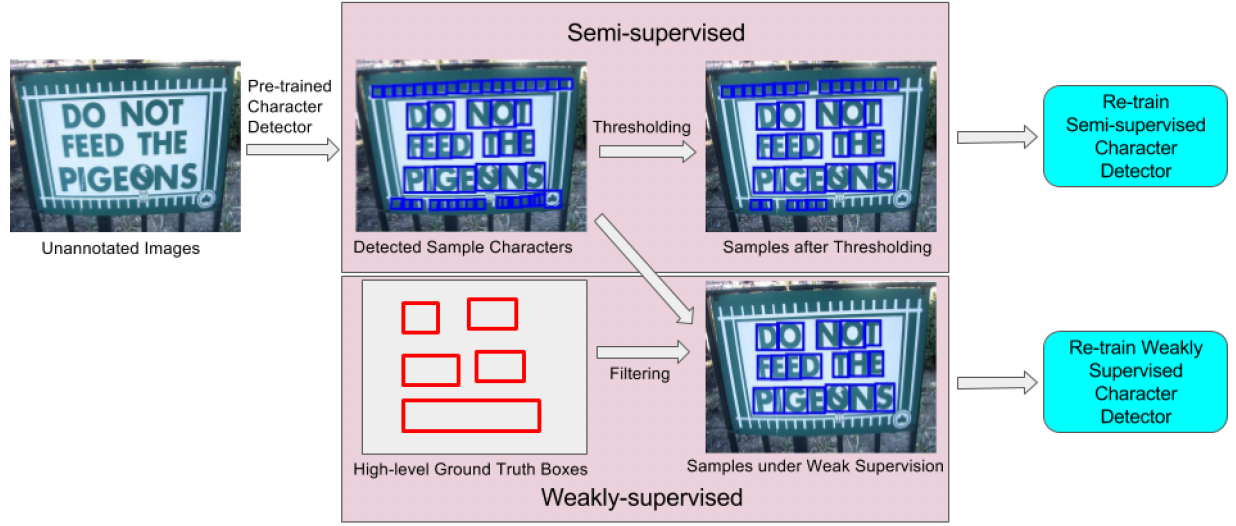
논문 제목: EAST: An Efficient and Accurate Scene Text Detector 연구 기관: Megvii Word box detection 의 정확성을 높이는 기술에 촛점을 맞춘 연구 논문이다 (인식 기술 자체는 본 논문의 연구 대상이 아니다). 저자는 지금까지의 word box detection 은 많은 프로세스 단계를 거쳐야 하므로, error propagation 문제가 있음을 지적하고 있다 (아래 그림에서 다른 기술들과 본 기술의 프로세스 구조를 비교하고 있다). 본 연구에서는 3 단계 프로세스 만으로 가장 우수한 multi-oriented word box detection 성능을 확보하였다고 주장하고 있다 (아래 그림 (e) 가 저자가 제안하는 기술 구조이다). Multi-oriented word box detection 은 문자열이 가로 방향이 아닌, 임의 방향으로 존재하여도 문제없이 검출하는 것을 의미한다 (가로 방향만 검출하는 것은 horizontal box detection 이다). [ Data Annotation ] Word 를 둘러싸는 임의 형태 사각형의 꼭지점 (직사각형 아님, 아래 그림 (a), 노란색 점선은 word 크기에 딱 맞는 사각형이며, 녹색 실선은 margin 을 두어 크기를 줄인 사각형), 임의 형태 사각형의 안쪽 영역을 나타내는 text score map (일종의 heat map, 아래 그림 (b)), 임의 형태 사각형을 둘러싸는 가장 작은 크기의 직사각형 (아래 그림 (c) 의 분홍색 선), heat map 영역 내의 각 포인트에서 직사각형 4변 까지의 거리 (아래 그림 (d)), 직사각형이 기울어진 각도 (아래 그림 (e)) 를 ground truth annotation 정보로 만들고 이를 추정한다. 임의 형태 사각형 정보는 word 크기에 딱 맞는 사각형 (아래 그림 (a) 노란색 점선) 및 margin 을 두고 축소시킨 사각형 (아래 그림 (a) 초록색 실선) 정보...